从强化学习到 DeepSeek R1
1. 什么是强化学习 (RL, Reinforcement Learning) ¶
传统的机器学习,包括深度学习,其本质是数学性的,严格遵守函数的数学定义:对于给定输入,产生确定的输出
随着输入 \(x\) 和输出 \(y\) 的不同,这一范式可以适配各种不同的任务,比如:
- \(x\) 是图像,\(y\) 是类别,那么 \(F\) 就是 Resnet 这种图像模型;
- \(x\) 是语音信号,\(y\) 是文字,那么 \(F\) 就是一个语音识别模型;
- \(x\) 是文本输入,\(y\) 是文本输出,那么 \(F\) 就是时下火热的大语言模型;
…
强化学习(Reinforcement Learning)的本质上则是哲学性的,它探讨三个核心问题:
- 我是谁?一个 Agent
- 我在哪?处于某个 State
- 到哪里去?采取一个 Action
如果站在上帝视角去观测这个 Agent,我们还会发现:
- Agent 处在一个环境中(Environment)
- Agent 有一个用来策略(Policy)告诉我该采取什么动作(Action)
- 每执行一个动作(Action
) ,环境都会给我反馈 (Reward)
以上就是强化学习中的主要概念。

2. 如何进行强化学习 ¶
这里以一个迷宫问题为例,介绍如何进行强化学习:
迷宫:(S: Start, E: End, W: Wall)
block-beta
columns 3
S1["S1(S)"] S2 S3["S3(W)"]
S4 S5 S6
S7["S7(W)"] S8 S9["S9(E)"]
这个迷宫就是一个 Environment。我们放置一个机器人在开始处(Start
2.1. Q-Learning¶
Q-Learning 是最早,也是最简单的强化学习算法。前文提到的策略 \(\pi(s)\) 过于抽象了,所以我们也定义以下表格
| 上 | 下 | 左 | 右 | |
|---|---|---|---|---|
| s1 | ||||
| s2 | ||||
| … |
我们称这张表为 Q 值表,表里边的元素 \(Q(s, a)\) 表示在状态 \(s\) 下,采取动作 \(a\) 的奖励 \(reward\)。基于这张 Q 值表,我们可以定义策略:
$$
\pi(s_i) \rightarrow \arg\max_a Q(s, a)|_{s=s_i}
$$
完成迷宫所需要的最小的Q值表如下:
| 上 | 下 | 左 | 右 | |
|---|---|---|---|---|
| s1 | -1 | 1 | -1 | 0 |
| s4 | 0 | -1 | -1 | 1 |
| s5 | 0 | 1 | 0 | 0 |
| s8 | 0 | -1 | -1 | 1 |
可以指挥 Agent 沿如下路径行进
block-beta
columns 3
S1["S1(S)↓"] S2 S3["S3(W)"]
S4["S4→"] S5["S5↓"] S6
S7["S7(W)"] S8["S8→"] S9["S9(E)"]但是我们很快发现 Agent 行进的路径并不唯一,比如以下路径也能让 Agent 走到终点
block-beta
columns 3
S1["S1(S)→"] S2["S2↓"] S3["S3(W)"]
S4["S4"] S5["S5↓"] S6
S7["S7(W)"] S8["S8→"] S9["S9(E)"]
这是强化学习的第一个问题,模型的解不唯一。稍后我们讨论这种解不唯一带来的问题。
2.2. Q-Learning 的学习过程 ¶
- Q 值表初始化,可以全部初始化为 0;
-
迭代学习:我们假设 Agent 被初始化在 S0 位置
-
选择 action
\[a = \pi(s_i) = \arg\max_a Q(s, a)|_{s=s_i}\] -
执行 action, 环境 Environment 给出下一个状态 \(s'与奖励\)r$
\[s',r = Environment(s, a)\] -
更新 Q 值,这里一般使用 Bellman 方程:
\[Q(s,a)\leftarrow Q(s,a) + \alpha [r+\gamma \max_{a'}Q(s',a')-Q(s,a)]\]
其中:
- \(\alpha\) 为学习率,控制 Q 值表的更新幅度;
- \(\gamma\) 为折扣因子,控制长期奖励与即时奖励的平衡;
-
Q-Learning 本质上就是记住当前格子的奖励,同时不断根据未来价值重新评估当前格子的价值。最优情况下,总是选择未来价值最高的动作。在学习过程中,每个格子的 Q 值总是依赖于其他格子的 Q 值,格子之间相互依赖,非常容易导致 Q 值长期震荡无法收敛。此时需要对学习过程进行精细挑参才能保证学习过程的收敛性。这是强化学习的第二个问题。
2.2.1. 利用和探索(exploitation & exploration)¶
如果单纯使用上述学习方法,很容易出现如下问题:
block-beta
columns 3
S1["S1(S)→"] S2["S2↓"] S3["S3(W)"]
S4["S4"] S5["S5↑"] S6
S7["S7(W)"] S8["S8"] S9["S9(E)"]即 Agent 在 S2 和 S5 之间反复震荡,无法真的走到终点 S9。其原因在于 Agent 只能获取其历史路径上的 Q 值,缺乏对整个世界(Environment)的认知,无法发现 S8 和 S6 这种更加靠近终点的路径。我们称这种利用历史知识的过程为“利用”(exploitation
除了“利用”以外,我们还需要让 Agent 有一定的“探索”(exploration)能力,保持对世界的好奇心。最常见的探索方法是使用 \(\epsilon-greedy\) 改造策略 \(\phi\):
即以概率 \(1-\epsilon\) 选择最优动作,以概率 \(\epsilon\) 选择随机动作。为了让 Q-Learning 更好的收敛,可以在训练过程中逐步降低探索概率 \(\epsilon\)。
2.2.2. 强化学习的目标 ¶
强化学习的核心目标是找到一个最优策略 \(\pi^*\),使 Agent 在其生命周期内获得的期望奖励最大化:
直接在策略空间优化 \(\pi\) 通常是不可行的:
- 策略空间过大:\(\pi(a|s)\) 是一个概率分布,极大的增加了搜索难度;
- 无梯度信息:不经过特殊设计,难以直接对策略求导;
为了解决上述问题,引入了 值函数 来简化优化过程,值函数一般有两类:
- 状态价值函数 \(V^\pi(s)\): 表示从某个状态 \(s\) 开始,遵循策略 \(\pi\) 后,所能获得的长期回报
- \(\gamma\) 为折扣因子,控制未来奖励的重要性;
- \(r_t\) 为时刻 \(t\) 的即时奖励;
- \(\mathbb{{E}}_\pi\) 表示对策略 \(\pi\) 的所有可能多做求期望。
Bellman 方程是上述值函数定义的递归形似,将上述定义拆解成了当前奖励和未来状态价值:
- 动作价值函数\(Q^\pi(s, a)\): 与状态价值函数类似,只是表示状态 \(s\) 下执行动作 \(a\) 后,能够得到的长期回报
-
\[ Q^\pi(s,a) = \mathbb{E} \left[ \sum_{t=0}^{\infty} \gamma^t r_t \mid s_0 = s, a_0=a \right] \]
2.2.3. 强化学习的挑战 ¶
-
训练样本的概率分布问题 传统的监督学习中,一般要求训练样本和测试样本独立同分布,即样本独立抽样,但样本来源的概率分布保持不变。这样才能让监督学习算法从数据里边总结和学习规律。而强化学习通过与环境交互来获取样本,Agent 的初始状态、运行轨迹都会影响采样过程。即不能保证两次训练之间的样本是独立同分布,也无法保证测试与训练的样本是独立同分布。
-
部分观测与环境随机性 强化学习训练过程只能对整个世界(Environment)进行部分观测,不能感知整个世界(没见过市面
) 。模型经常出现对局部过度学习、过拟合,对全局欠拟合。由于无法界定过拟合和欠拟合部分的边界,难以保证 Agent 在未见过的新环境中行为的合理性和稳定性。 -
延迟反馈与稀疏奖励 在许多强化学习问题中,奖励信号往往是延迟且稀疏的,导致 Agent 难以及时判定行为的好坏。这种激励信号的不连续性使得价值函数估计方差变大,会增加优化难度,必须采用奖励整形、经验回放等策略来缓解这一问题。
3. 策略梯度方法 ¶
在介绍策略梯度方法之前,我们先来看值函数方法的几个问题:
- 只适合离散状态与动作空间
- 需要额外组合探索策略
- 随机探索对最坏情况缺乏控制;
而策略梯度方法是直接对策略进行求导的方法,首先需要将策略函数参数化 \(\pi(a|s) \rightarrow \pi_\theta(a|s)\),此时可以将强化学习的目标函数写为
这里:
- \(\tau = (s_0, a_0, s_1, a_1, ..., s_T, a_T)\) 是一个轨迹;
- \(R(\tau) = \sum_{t=0}^{T} r(s_t, a_t)\) 是轨迹的概率分布;
- \(p_\theta(\tau)\) 是轨迹的概率,由策略概率和环境的转移概率组成;
3.1. 策略梯度定理 ¶
策略梯度可以根据策略梯度定理计算
其中,\(\nabla_\theta \log \pi_\theta(a_t|s_t)\) 是策略的梯度,通过这个梯度可以更新策略在状态 \(s_t\) 下采用 \(a_t\) 的概率。而 \(R(\tau)\) 表示策略带来的未来回报,回报越高动作被采纳的概率越高。估计未来回报是计算策略梯度最重要的步骤,常见实现有两种:
- 使用蒙特卡洛方法估计 \(Q_\pi(s,a)\),由于不需要使用模型,也称为无模型策略梯度算法;
- 通过引入价值函数(\(V_\pi\) 或者 \(Q_\pi\))来估计未来回报;
策略梯度方法对比值函数方法,具备如下特点:
- 可以基于轨迹学习,而不需要实时交互和反馈
- 适合高维连续动作空间(包括 embedding 空间)
- 可以把序列生成模型可以作为策略:
- 用户输入作为状态空间 S;
- 模型输出作为动作空间 A;
- 模型参数作为策略参数 \(\theta\);
给出人类偏好反馈 \(R(\tau)\) 即可直接使用 PG 方法训练 LLM 对齐人类偏好。但 PG 算法的梯度方差较大,稳定性欠佳。同时 \(R(\tau)\) 也难以直接定义、打分,因此 PG 方法并未实际应用于 LLM 对齐任务。
3.2. 策略梯度方法的改进–TRPO(Trust Region Policy Optimization)¶
当把策略梯度方法应用于训练时,可以通过下式计算 minibatch 梯度:
最大化累计奖励,需要使用梯度上升方法对参数进行更新:
策略更新如何选择步长 \(\alpha\) 是一个非常关键的问题:
- 过大的步长会导致策略剧烈变化,破坏已学到的好的行为
- 过小的步长会导致训练效率低下
常见的步长选择方法有三种:固定步长,线性搜索和信赖域,以下是三种方法的图示:
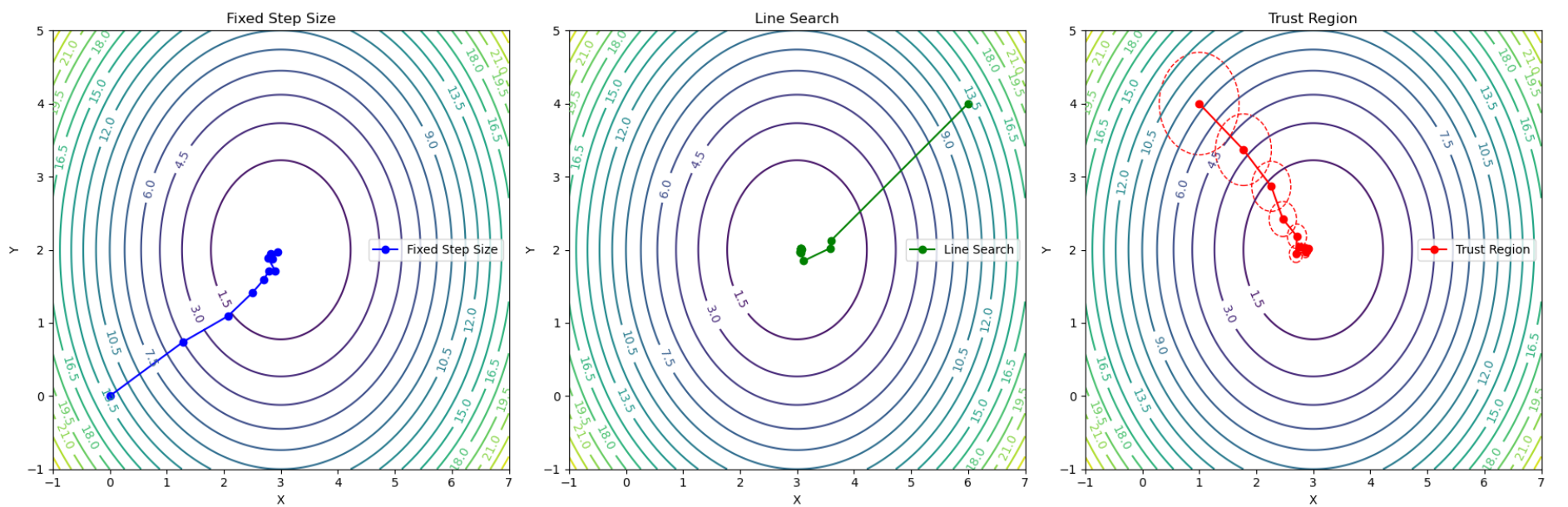
固定步长方法是最为朴素的方法,但是步长会影响收敛性和稳定性,对实际问题搜索合理步长会比较麻烦;线性搜索会沿着梯度方向尝试多个步长,并选择最优步长,搜索开销较大,但效果最好;信赖域方法会根据梯度计算自适应信赖域,并保证在信赖域内更新。信赖域方法一方面能够保证每一步更新不会距离原策略太远,另一方面能够在梯度噪声过高时自动缩小信赖域,能够比较好的解决 PG 方法梯度噪声高问题。
优势函数 ¶
上边讨论的步长搜索算法都在某种程度上要求目标函数具备凸性,而强化学习的目标显然不是凸函数。为了解决目标函数凸性的问题,TRPO 又引入了 Minorize-Maximization 思想 :对于一个难以优化,难以求导的目标函数,可以选择一个替代函数来描述目标函数的上届,通过迭代最大化这个上届替代函数可以完成对原目标函数的优化。
什么是凸性
凸性 是优化理论中最为重要的一个概念。若一个函数满足任意亮点 \(x_1\) 与 \(x_2\),满足:
$$
f(\lambda x_1 +(1-\lambda)x_2) \le \lambda f(x_1) + (1-\lambda)f(x_2)
$$
则函数具有凸性。具备凸性的函数局部最优等价于全局最优,因此基于凸性有一系列高效的优化算法。
为了构造这个替代函数,我们引入一个优势函数的定义:
这个函数表示策略 \(\pi\) 采取动作 \(a\) 时的奖励比平均奖励高多少。TRPO 最终求解的问题就变成
$$
\begin{aligned}
\max_{\theta} & E[\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)} A_\theta(s,a)] \
\textrm{s.t.} & E[D_{KL}(\pi_{\theta_{old}}(a|s) \pi_\theta(a|s))] \le \delta
\end{aligned}
$$
其中,\(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}\) 是 重要性采样 。由于训练时只能使用旧策略产出的轨迹,我们需要通过重要性采样对目标函数中的期望进行修正,使其能够反映新策略的期望回报。
3.3. 策略梯度方法的改进–PPO(Proximal Policy Optimization)¶
近端优化(Proximal Optimization)是这样一种优化方法:通过引入一个近端约束项,让优化迭代过程中步长尽可能小,避免因权重剧烈变化而带来的训练不稳定。Proximal OPtimization 在传统的凸优化领域有着广泛的应用。
$$
\theta^* = \arg \max_\theta \left(
f(\theta) + \lambda |\theta - \theta_t|_p
\right)
$$
其中\(p \in \{1, 2\}\),常见使用\(L_1\)或者\(L_2\)作为约束项。
PPO 通过 clip 操作限制策略的更新幅度
$$
J_{PPO}(\theta) = \mathbb{E} \left[
\min(
\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}A(s,a),
clip(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}, 1-\epsilon,1+\epsilon) A(s,a)
)
\right]
$$
其中\(clip()\)函数会将\(\frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)}\)这个比值限制在\([1-\epsilon,1+\epsilon]\)。
TRPO 算法在计算信赖域时需要计算 Fisher 信息矩阵,并使用共轭梯度方法来更新,计算量较大。而 PPO 仅需要对重要性采样进行截断,更加的高效和稳定。
优势函数的估计 ¶
在进行优势函数(Advantage Function)估计的时候,通常有两种方法:蒙特卡扩估计与时间差分估计:
- 蒙特卡洛估计:通过完整回报近似 \(Q(s,a)\),需要完整的轨迹才能计算,一般用于离线数据
- 时间差分估计:通过折扣未来奖励来近似 \(Q(s,a)\),可实时更新
蒙特卡洛估计可以给出无偏估计,但是优势函数的方差较大,而时间差分方差较小,但误差偏差较大。为了平衡两者 PPO 引入了 GAE(Generalized Advantage Estimation
其中 \(\delta_t\) 是 \(t\) 时刻的 TD 残差
参数 \(\lambda\) 用来控制蒙特卡洛估计与时间差分估计之前的权衡:
- \(\lambda\) 越大越趋向于未来奖励,更倾向于蒙特卡罗方法,提供高方差低偏差的估计;
- \(\lambda\) 越小越趋向于即时奖励,更加倾向于时间差分方法,提供低方差但高偏差的估计;
RLHF with PPO¶
RLHF 巧妙的在 PPO 框架下引入了人类反馈(Human Feedback
- Actor Model: 演员模型,就是需要对齐的 LLM 模型,用于提供策略 \(\pi(a|s)\);
- Critic Model: 评论家模型,用于估计总收益 \(V_t\);
- Reward Model: 奖励模型,用于估计计算即时收益 \(R_t\);
- Reference Model: 参考模型,用于提供训练阶段的约束,防止模型训歪(用于计算 KL 散度
) ;
训练时,RM 模型需要独立训练,而 Actor Model 与 Critic Model 则是在 PPO 的过程中一起训练。如果两者共享参数,但是使用不同的 head,我们也称 Actor Model 为策略网络,Critic Model 为值网络。
RLHF 的过程相当繁琐,并且训练过程也并不非常稳定,因此 LLaMa 系列模型在开始的时候仅使用了 SFT,但是在 LLaMa2 时又重新引入了 RL 进行偏好对齐,提升用户体验。
3.4. 策略梯度方法的改进–GRPO(Group Relative Policy Optimization)¶
PPO 算法中的值函数只对最后一个 token 评估,复杂并且引入额外的不确定性。GRPO 能够避免值函数估计,使得整个训练过程更加简单,具体来说:
对于每个问题 \(q\),生成 \(G\) 个回答 \(o_i, i\in[1..G]\),每个答案的长度为 \(|o_i|\)。
GRPO 引入了一种全新的优势函数定义:
即第 \(i\) 个输出的奖励 \(r_i\),相对整个 Group 的优势,该式与 Batch Normal 极为类似。计算这个优势函数只需要计算每个输出的奖励即可,无需再估计值函数。
DeepSeek R1¶
奖励是 GRPO 整个训练的信号来源,DeepSeek R1 在训练中主要使用基于规则的奖励。一方面基于规则的奖励能够节约训练资源,另一方面也能避免 Reward Hacking 问题。
什么是 Reward Hacking
Reward Hacking 是指强化学习训练时,Agent 通过不符合预期的方式,利用奖励函数的漏洞来最大化其奖励,从而破解训练过程。产生 Reward Hacking 的主要原因在于奖励函数本身不完美,特别是一些基于规则设计的复杂奖励函数,在不限定可行域的时候,经常会导致 Agent 尝试逃逸到非可行域,从而获得超额奖励。
DeepSeek R1-Zero¶
DeepSeek R1-Zero 是纯粹基于强化学习训练的模型,主要采用了两种规则奖励:
-
Accuracy Rewards:主要同归规则,比如文本匹配和正则表达式来给出奖励,针对 LeetCode 甚至会使用 compiler 作为奖励反馈的来源;
-
Format Rewards:奖励模型将思考过程放入
<think>...</think>标签中;
在训练的过程中,使用了如下的模板:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: prompt. Assistant:
在 R1-Zero 的训练过程中,可以看到模型在 Reasoning Task 上持续稳定则性能改善。并且观测到了 Aha-Moment。
Aha Moment
Aha Moment 是指某个人突然理解或者领悟某个概念、问题或者想法的瞬间,中文可以称作“顿悟”时刻,使得对某个问题的解决有一个飞跃。

虽然 R1-Zero 表现出了很轻的 Reasoning 能力,但其输出的可读性较差,并且会中英文。为了让模型的体现更好,又开发了 R1,加入 human-friendly 的冷启动数据。
DeepSeek R1¶
Cold Start¶
使用数千条长 CoT 数据对模型进行微调:
- 数据可读性:主要解决多语言混合问题与 Markdown 格式缺失问题;
- 潜力:基于人工先验设计数据;
Reasoning RL¶
使用 RL 提升模型的 Reasoning 能力,为了避免多语言混合,引入了惩罚项。
拒绝采样与 SFT ¶
主要为了提升 Reasoning 以外的能力,比如写作和对话,通过 SFT 来实现。数据主要包含:
- Reasoning 数据:使用生成式 Reward 函数,将 ground truth 和模型输出同时输入给 base 模型进行判断;以此种方式收集 60W 训练数据;
- Non-Reasong 数据:使用 prompt 让模型为 writing、QA 等任务添加 CoT,并收集 20W 输出作为训练数据;
RL for all scenarios¶
再次通过 RL 提升模型的 helpness 和 harmlessness。